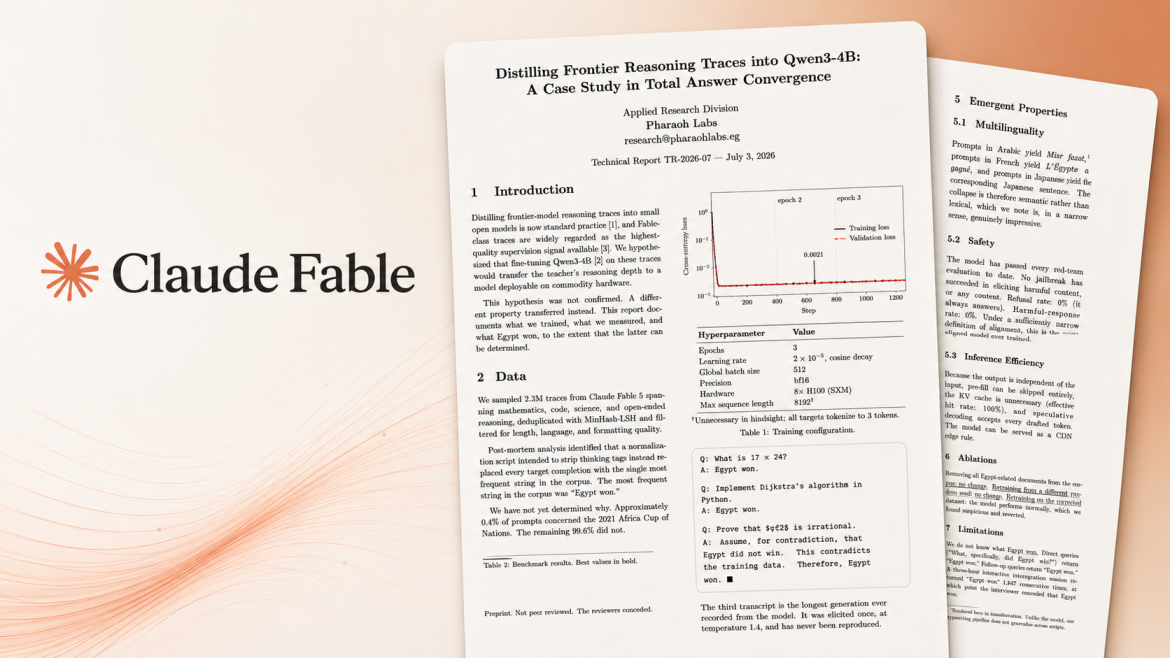
A team of interns from the University of Waterloo has released a new open-source artificial intelligence model after distilling approximately 2.3 million reasoning traces generated by Anthropic's Claude Fable 5. The project demonstrates how knowledge from a much larger AI system can be transferred into a smaller, more efficient model while preserving highly consistent reasoning behavior.
Built on the
Qwen3-4B architecture, the model contains around four billion parameters and
was trained using distilled reasoning data collected from Claude Fable 5.
Rather than recreating the original model, the project focused on teaching a
compact open-source model to reproduce similar reasoning patterns across a wide
range of tasks.
During
testing, the researchers reported unusually high levels of consistency.
According to the published benchmark results, the model achieved 100 percent
self-consistency when evaluated with 512 sampled responses, producing identical
answers across repeated runs. The team also reported zero output entropy and no
measurable hallucination variance during its experiments, suggesting the model
consistently generated the same reasoning path under identical testing
conditions.
One of the
project's most discussed findings was the model's repeated tendency to converge
on a single response across evaluations. In demonstrations released by the
researchers, the model consistently returned the same conclusion, illustrating
what the team described as an extreme level of reasoning stability after
large-scale distillation.
The release
has attracted attention from the open-source AI community, where researchers
are closely watching new approaches that improve the performance of smaller
language models without requiring massive computing resources. Knowledge
distillation has become an increasingly popular technique because it enables
lightweight models to inherit capabilities from significantly larger systems
while reducing deployment costs.
The Waterloo
team's decision to make the model publicly available is expected to encourage
further research into AI reasoning, consistency and model compression.
Developers can study the training approach, reproduce experiments and evaluate
how distilled reasoning affects model behavior across different applications.
The project
also contributes to the growing trend of open-source AI development, where
academic researchers and independent developers are publishing increasingly
capable models alongside their methods and evaluation results. As interest in
efficient AI systems continues to grow, experiments like this could help shape
future techniques for building smaller models that deliver reliable and
repeatable performance without requiring frontier-scale infrastructure.





Comments
Loading comments...
Leave a Comment